
Rベース予測モデル×Alteryxの活用術!卒業生の寄付行動を予測する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちはゲームソリューション部のikumiです。
AlteryxにはStarter Kitsという、誰でもすぐに分析できる構築済みのサンプルワークフローが用意されています。
前回の記事ではLifetime Valueを算出するサンプルワークフローの紹介を行いました。
今回の記事では、別のスターターキットであるPredictive Analytics Starter Kitに含まれる、『New Donor Score Sample』のワークフローを紹介していきます。当ワークフローには予測ツールを使用しておりますので、実際にサンプルワークフローを確認する際は予測ツールパッケージのインストールを実施してください。
サンプルワークフローの概要
今回のワークフローは、Rベースの「ランダムフォレストツール」という予測ツールを使って、大学に寄付してくれそうな卒業生がいるかどうかを予測するワークフローとなっています。
ランダムフォレストとは
ランダムフォレストは一般的な機械学習の一種で、複数の決定木を組み合わせて全体のモデルを構築します。私自身機械学習には疎いので本記事ではランダムフォレストについては詳細に説明しませんが、要は決定木モデルを組み合わせてより良いモデルを構築するアルゴリズム、ということだそうです。
なお、参考にしたブログは以下となりますので、気になる方はご参照ください。
また、Alteryxのランダムフォレストツールの公式ドキュメントは以下となります。
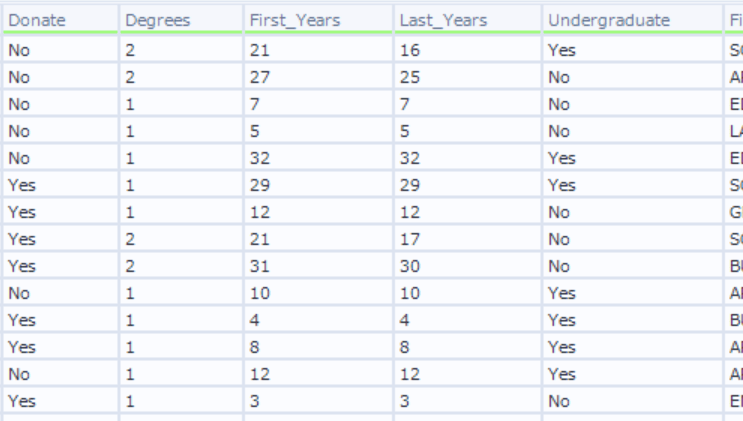
入力データ
予測の学習とスコアリングに利用するデータとなります。Donate列には既に過去の寄付実績が入っています。このデータからサンプルを取得しモデルを作成することで、一度も大学に寄付したことがない人が寄付をする確率を予測するよう設計していきます。
ワークフローの処理ステップ
ワークフローで行っている処理の流れは以下の通りとなっています。ここでは処理内容を詳細に解説しませんので、実際にStarter kitsをダウンロードして確認してみることをお勧めします。
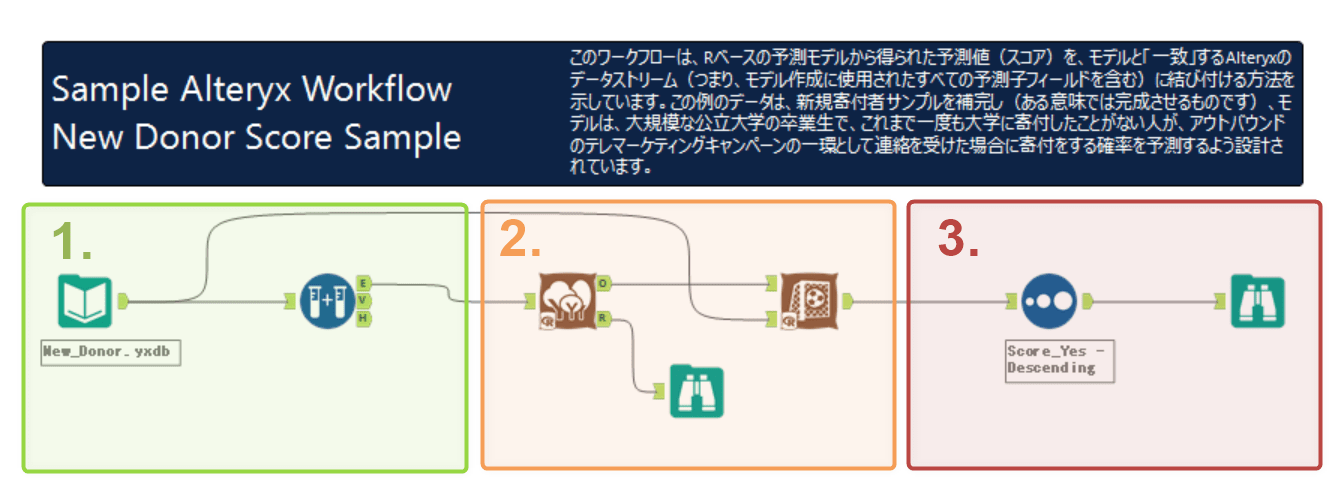
- データの前処理:データを入力し、入力データからサンプル作成ツールで学習用データを抽出します
- 予測分析(ランダムフォレスト)、スコアリングの実行
- アウトプット整形
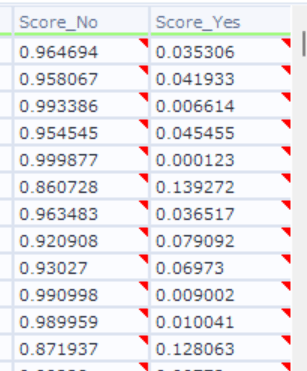
出力結果では、寄付をする確率(Score_YES/No)がそれぞれ算出されていることを確認できました!
さいごに
いかがでしょうか。非常にシンプルなステップで予測分析を実装できました。このように事前に予測できると、マーケティング施策などの確度が高められたりと、色々なシーンで活用できそうですね。










